R语言学习笔记23
直方图与密度估计
条形图(barplot)反映分类变量的频数分布或者比例, 直方图(histogram)反映连续取值的数值变量的分布。 geom_histogram()作直方图, 可以自动选取合适的分组个数, 也可以人为指定分组个数。
ggplot2包中的midwest数据集包含了美国中西部的一些县的统计数据, 如面积(单位:平方英里)。 下面的程序对连续取值的数值型变量area作频数直方图, 自动确定分组个数:
p <- ggplot(data = midwest, |
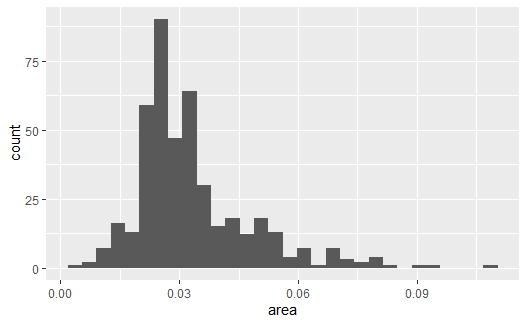
上面图形的纵坐标是频数(count),是每个组的频数。 geom_histogram()默认调用stat_bin()进行分组及频数统计。
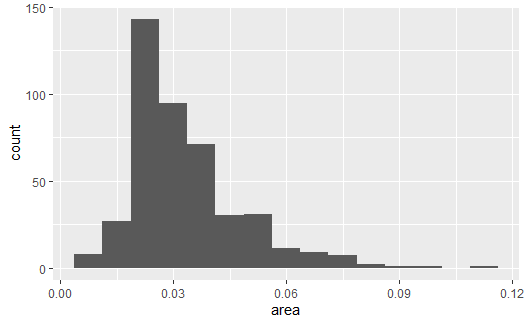
直方图的形状比较依赖于分组数与分组起始点位置, 可以用bins参数控制分组数, 用binwidth参数控制分组宽度, 用center或者boundary参数控制组中心或者组边界对齐位置, 如:
p + geom_histogram(bins = 15) |
可以利用fill映射将构成直方图的观测按照某个分类变量分组, 然后每个条形内部按照该分类变量的值分段染色, 段内各颜色的长度代表该条形所在组某一类的频数, 如:
midwest_sub <- midwest %>% |
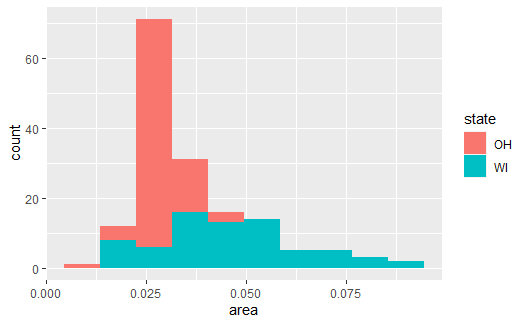
可见面积较小的县主要来自OH州, 面积较大的县主要来自WI州。
geom_density()可以对连续变量绘制密度估计曲线,如:
p <- ggplot(data = midwest, |
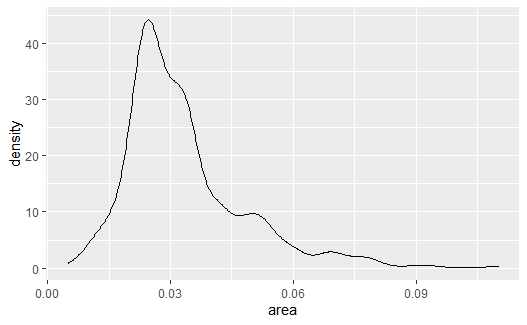
# 制作每个州的各县的面积密度估计, 画在同一坐标系中 |
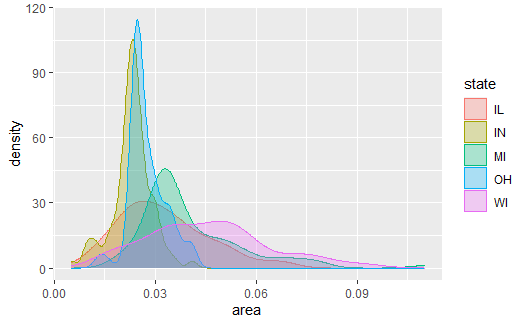
可以看出,IN与MI州各县的面积偏小。 WI州各县的面积较大。
p <- ggplot(data = midwest, |
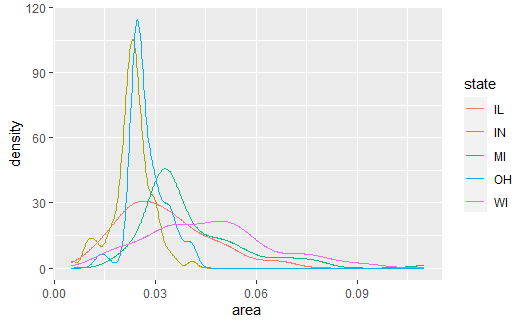
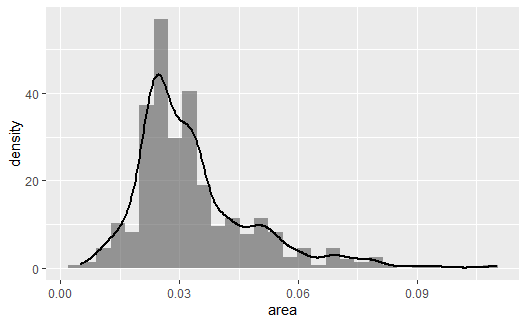
geom_density()的纵轴是密度估计。 为了能够将直方图与密度估计画在同一坐标系中, 需要将直方图的纵轴也改为密度估计,如:
p <- ggplot(data = midwest, |
 微信
微信 支付宝
支付宝
相关推荐

评论