R语言学习笔记22
数据变换与条形图
ggplot2中的条形图函数geom_bar()可以对一个分类变量自动统计频数, 并作频数条形图。 比如对gss_sm数据集的bigregion变量作频数条形图:
library(socviz) |
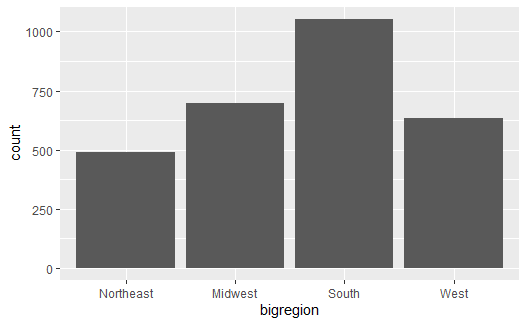
结果是每个大区的受访者人数的条形图。 图形中x映射是用户指定的, 而y轴则是自动计算的频数。 实际上, geom_bar()自动调用了统计函数stat_freq()对每个大区计算频数, 生成新变量count和prop。 geom_bar()默认使用count(频数)。
虽然ggplot2能够自动统计频数, 但最好还是预先统计好频数, 仅用ggplot2绘图。 所以,上例可以用tidyverse的count和ggplot2的geom_col改写成:
# library(tidyverse) |
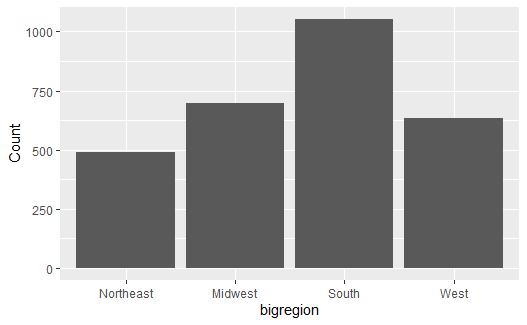
mutate用法参考:https://blog.csdn.net/lanfengchalan/article/details/68946175
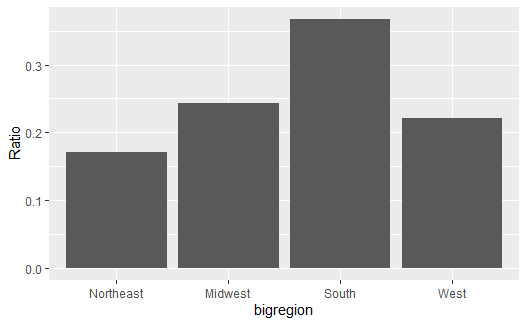
下面的程序将纵坐标改成了比例:
p <- ggplot(data = df1, |
作gss_sm数据集中religion变量的频数条形图, 并给不同的条形自动分配不同的颜色, 方法是指定fill = religion:
df2 <- gss_sm %>% |
p <- ggplot(data = df2, |
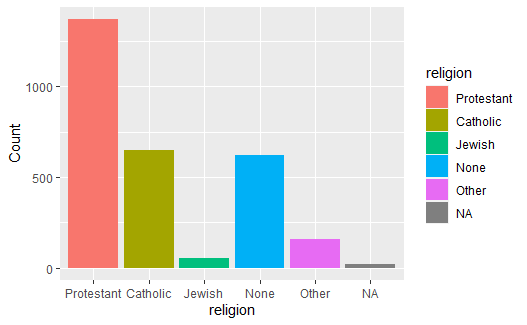
因为将religion同时映射到x维与fill维, 所以对应fill维在图形右侧出现了图例,图例对应的函数是guides()。 调用guides(fill = FALSE)可以人为指定不做关于填充色的图例:
p + geom_col() + |
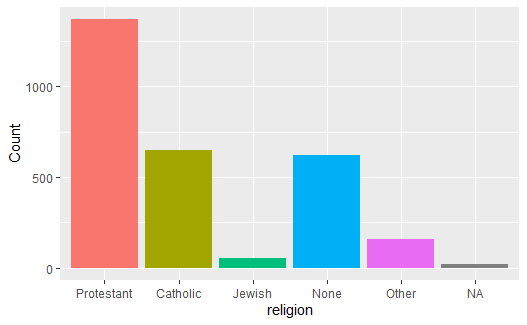
从可视化理论的角度看, 上图中的不同颜色是多余的, 用同一颜色更能强调数据本身。
分段与并列条形图
面的条形图展现了单个分类变量的频数分布。 两个分类变量的交叉频数分布可以用分段条形图或者并列条形图表现。
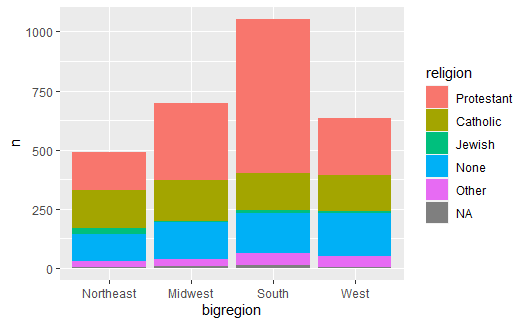
例如,对gss_sm数据集, 按照bigregion分组计算频数, 每组内再按照religion计算频数, 用tidyverse统计后作图如下:
df3 <- gss_sm %>% |
p <- ggplot(data = df3, |
# 将大类的高度拉平, 图形仅表示每一大类内部小类的比例, 没有大类频数信息, 也不能比较两个大类之间的小类频数, 但可以大致地在大类之间比较小类的比例 |
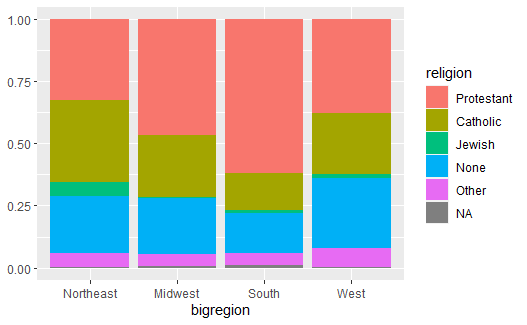
上面的程序在geom_col()中用了position = "fill"选项。
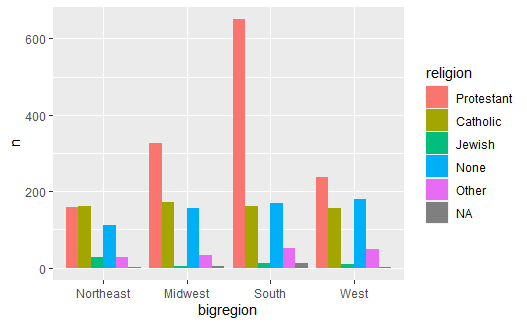
并排的条形图可以表现每个交叉类的频数, 可以比较容易地比较每个大类内部的小类比例以及小类的频数, 但是不容易比较大类的比例:
# 将各小类分开展示 |
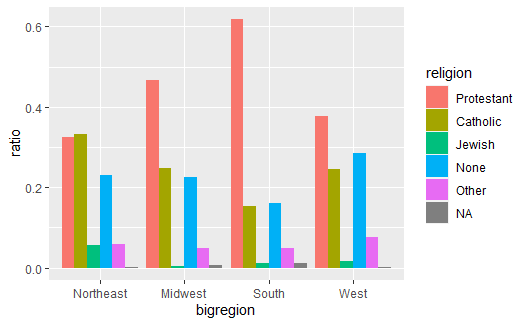
将上图中的纵轴改为大类内的比例(每个大区的比例之和等于1):
p <- ggplot(data = df3, |
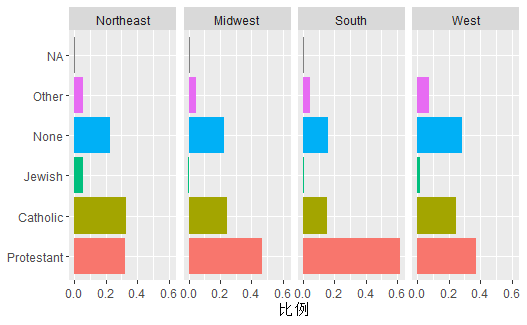
为了在不同大区之间比较宗教比例分布, 可以借助于小图, 将每个大区分配到一个小图:
p <- ggplot(data = df3, |
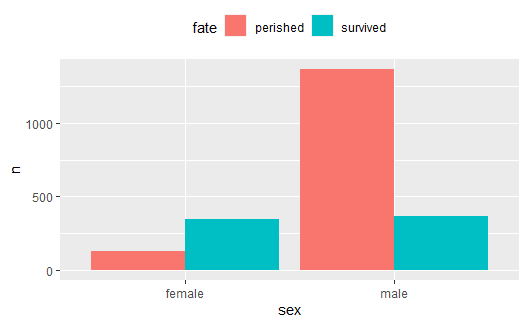
有时用来绘图的数据已经是一个频数表, 比如泰坦尼克号乘客生存与性别的频数表:
titanic |
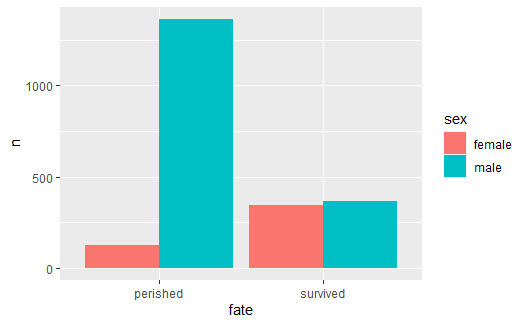
也可以按照性别分成大组:
p <- ggplot(data=titanic, mapping = aes( |
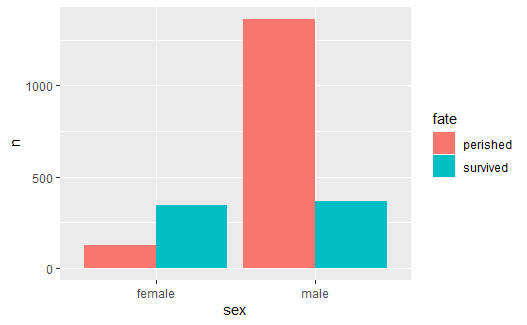
用theme()函数的legend.position参数可以指定图例的位置,如:
p + geom_col(position = "dodge") + |
# 做成堆叠形式: |
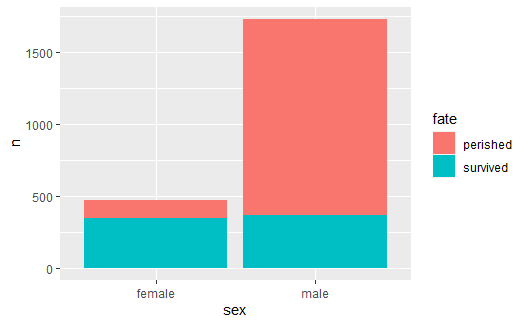
position = "stack"也是geom_col()函数的默认选项。
datasets包的Titanic数据集包含了泰坦尼克号乘客更详细的信息。 我们按照存亡结果和舱位等级分小图作男女频数条形图:
titanic2 <- as.data.frame(Titanic) %>% |
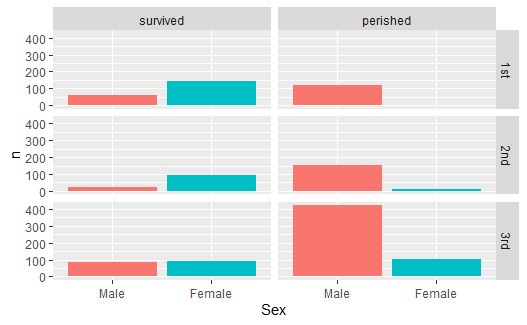
这里将fill映射到了Sex, 使得表示男女的条形填充了不同的颜色。 如果不满意上面的颜色, 可以用scale_fill_manual()函数人为地指定颜色、对应离散值和图例标签。 R扩展包colourpicker提供了很好交互图形界面用来挑选颜色。
条形图的其它应用
geom_col()不仅限于画频数或者比例的条形图, 此函数可以将一般用折线图表现的内容画成条形图, 但一定要注意一点:y坐标轴必须从0开始, 这也是geom_col()和geom_bar()函数默认的设置。 如果坐标轴不从零开始, 则条形的长度就不能正确表示对应的y变量数值。
举一个用条形图表示不是频数和比例的量的例子。 socviz包的oecd_sum数据集包含各年的美国以及OECD国家的期望寿命:
head(oecd_sum) %>% |
| year | other | usa | diff | hi_lo |
|---|---|---|---|---|
| 1960 | 68.6 | 69.9 | 1.3 | Below |
| 1961 | 69.2 | 70.4 | 1.2 | Below |
| 1962 | 68.9 | 70.2 | 1.3 | Below |
| 1963 | 69.1 | 70.0 | 0.9 | Below |
| 1964 | 69.5 | 70.3 | 0.8 | Below |
| 1965 | 69.6 | 70.3 | 0.7 | Below |
用geom_col()作diff变量的条形图, 并按照hi_lo变量对正负差值分别使用不同颜色:
p <- ggplot(oecd_sum, mapping = aes( |

 微信
微信 支付宝
支付宝
