R语言学习笔记21
连续变量的颜色映射
也可以将连续变量映射为渐变色。 除了表示二元函数的等值线图以外这种方法并不利于读者认读。
例如, 将人口数取自然对数映射为渐变色:
# library(ggplot2) |
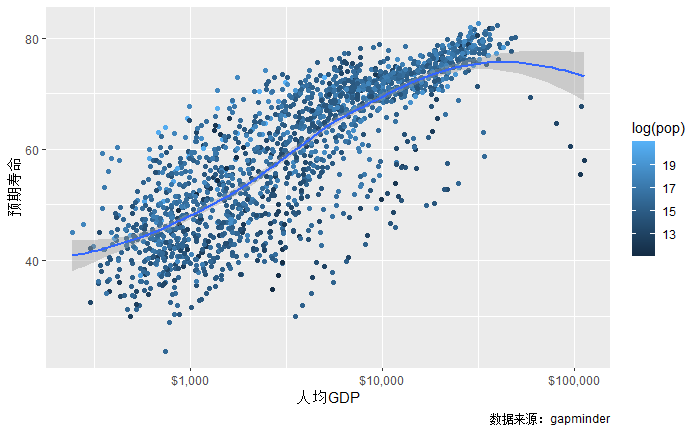
这里不同散点的颜色是连续变化的, 右侧的图例仅显示了有限的一些代表值。
保存图像
如果使用Rmarkdown制作图文, 图像会自动进入编译的结果(如PDF、Word、HTML)中, 图像大小、输出大小可以用Rmarkdown的设置调整。
为了将最近生成的图形保存为PNG格式,用命令如
# 生成上一张图(人口数取自然对数映射为渐变色) |
# 保存为pdf格式 |
保存为pdf文件时,如果图像中有中文会显示不出。
可以将制作的图形保存到了一个R变量中, 在ggsave()中可以用plot=参数指定,如
# 也是保存为一个png的图像 |
在ggsave()中可以用scale =指定放大比例, 用height =指定高度, 用width =指定宽度,用units =指定高度和宽度的单位,如:
ggsave(filename="文件名.pdf", plot=ggout01, |
单位可以是in, cm, mm。
折线图、分组、小图
图形中的分组和折线图
考虑gapminder数据集中每个国家的期望寿命随时间(年)的变化。 用geom_line()可以画折线图。 因为有许多国家,所以仅指定x、y变量无法得到所需图形,如:
p <- ggplot(data = gapminder, |
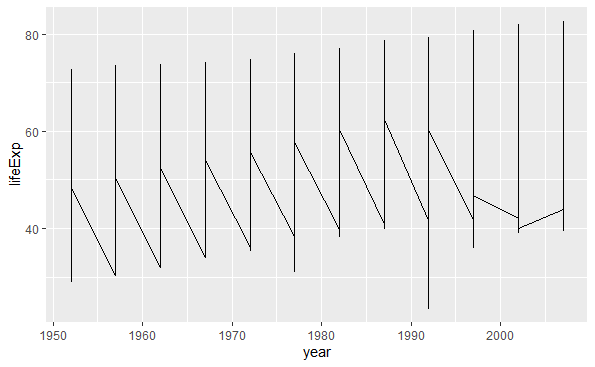
没有得出我们希望的每个国家一条曲线的效果。 这是因为程序中没有指定需要按照国家分组, 使得同一年的不同国家的坐标连成了一条竖线。
要注意的是, geom_line()会自动将x坐标从小到大排序, 然后再连接相邻的点。 如果希望按输入数据的次序连接相邻的点, 需要用geom_path()函数。
为了解决上图的问题, 加入按照国家分组的设定。 实际上, 分组(group)与x、y、color、fill一样可以映射到一个变量, 但仅能映射到分类变量。 上述程序的改进如下:
p <- ggplot(data = gapminder, |
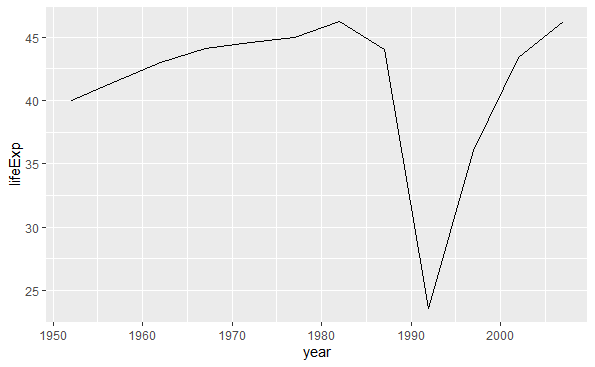
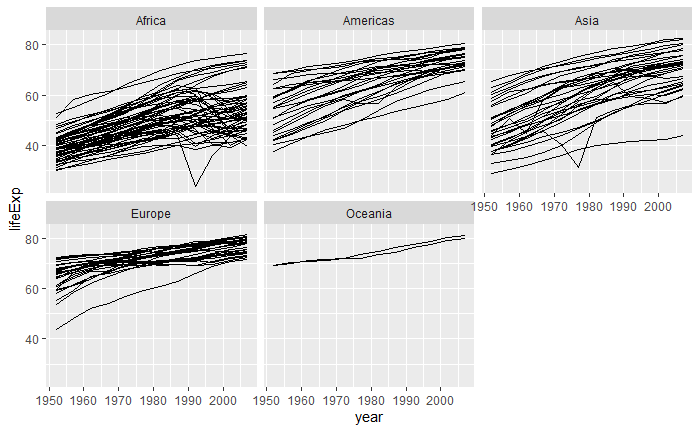
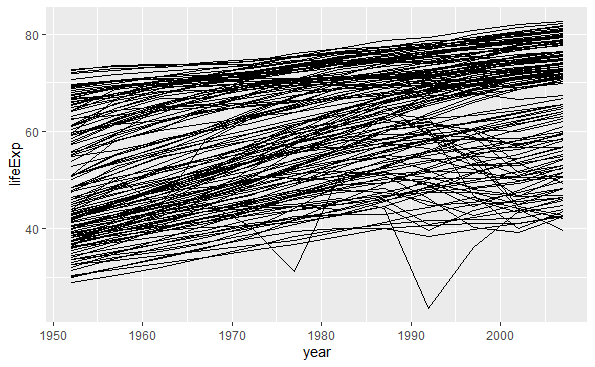
结果图形中每一条曲线对应一个国家。 为了查探其中最下方的不稳定曲线是哪一个国家,使用筛选观测的功能:
filter(gapminder,lifeExp < 30, year >=1990) |
# A tibble: 1 x 6 |
该国家为Rwanda。
如果需要按照两个或多个分类变量交叉分组, 可以给group维指定interaction(…), 其中…是分类变量表。
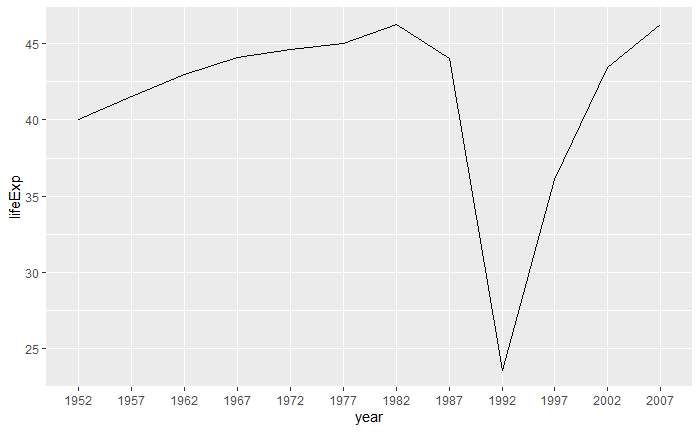
geom_line()用来绘制从左向右连接的折线。 比如, 仅绘制Rwanda的期望寿命时间序列:
p <- ggplot(data = filter(gapminder, country == "Rwanda"), |
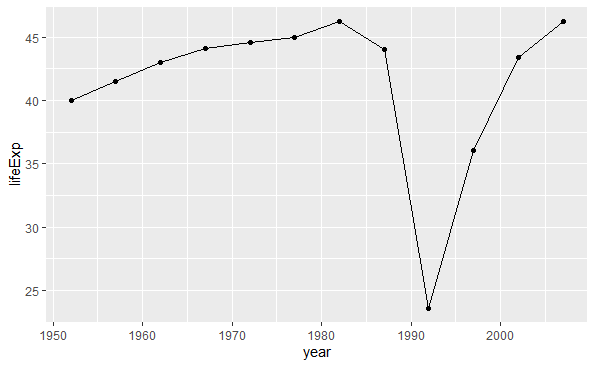
如果需要每个点画出散点符号, 可以同时使用geom_point()
p + geom_line() + |
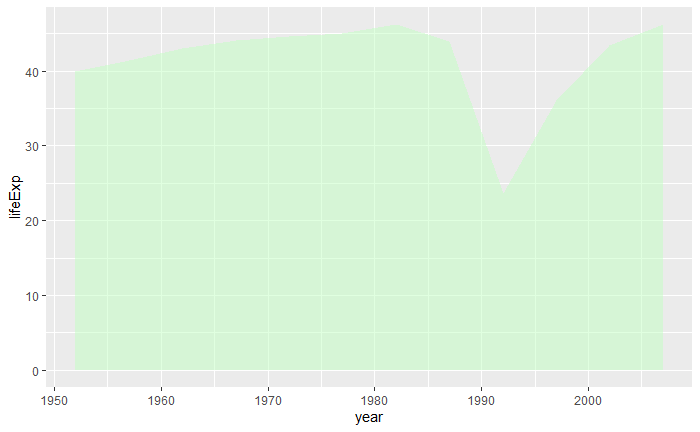
用geom_area()作类似图形, 但在折线下方填充颜色:
p + geom_area(fill = "darkseagreen1", alpha = 0.5) |
连线图还有一个问题, 就是如果x坐标不是数值型变量而是因子或者字符型, 则两点之间不会相连。 比如,将gapminder的Rwanda子集中的year转换成因子,再画折线图:
d <- filter(gapminder,country == "Rwanda") %>% |
没有得到应有的结果。 这是因为因子year起到了分组作用, 相当于每个年份为一组, 连线只能在组内连, 但每组仅有一个观测。 这时, 显式地指定group变量可以解决问题:
d <- filter(gapminder,country == "Rwanda") %>% |
对于折线图, 可以在geom_line()函数中用color参数指定颜色, 用linetype参数指定线型, 用size参数指定以毫米为单位的粗细。 线型包括:
- 0:不画线;
- 1:实线;
- 2:dashed;
- 3:dotted;
- 4:dotdash;
- 5:longdash;
- 6:twodash。
小图(facet)
可以将一个作图区域拆分成若干个小块, 称为小图(facet), 按照某一个或两个分类变量的不同值将数据分为若干个子集, 每个数据子集分别在小图上作图。
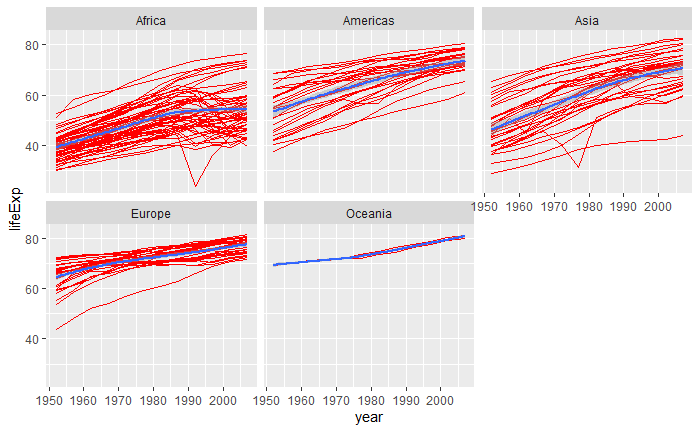
对于上面的例子, 可以将每个大洲的图形分别放置在一个小图上。 小图不是一种变量映射, 而是一种图形摆放方法, 所以不设置在aes()函数内, 而是用facet_wrap()函数规定。 这种功能与group映射的功能有些重复, 所以有时需要与group映射配合使用, 有时则不需要。
# 分组信息最好不要放在ggplot()中 |
可以将group分组信息放在geom函数中映射
p <- ggplot(data = gapminder, |
特别是在添加geom_smooth时,否则会为每一个州的每一个国家添加拟合曲线
p <- ggplot(data = gapminder, |
如果将group分组放在ggplot函数中统一映射:
p <- ggplot(data = gapminder, |
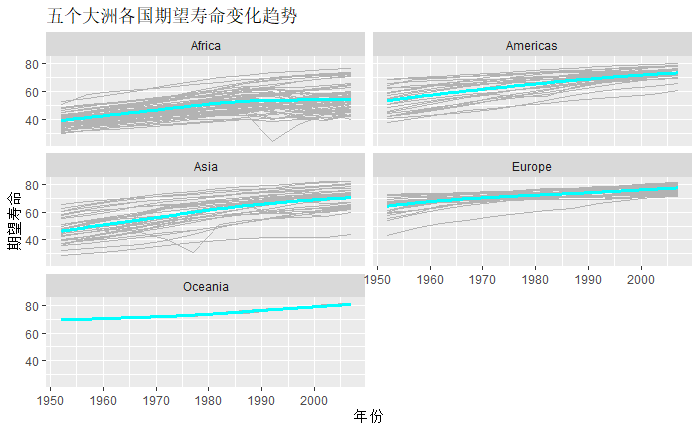
可以看到,每个国家都会有一条拟合曲线
区分不同小图的标签写在每个小图的上方。 可以用facet_wrap()参数strip_position和参数switch调整标签的上下左右。
小图之间默认公用了横坐标和纵坐标且坐标范围保持一致。 如果不保持一致, 读者可能会有误解。 但是x轴或y轴映射为分类变量且不同小图的分类完全不同时, 可以令各小图中该轴的取值不统一。 facet_wrap()选项scales默认为"fixed", 即所有小图的x轴、y轴都范围一致, 取"free_x"则允许各小图的x轴不统一, "free_y"允许各小图的y轴不统一, "free"允许各小图的x轴和y轴都不统一。
在facet_wrap()中可以用ncol参数指定小图的列数, 用nrow指定小图的行数。 各个小图的次序应该设定为一定的合理次序, 比如用来分类的变量本身有序, 或者令各小图中的数据值有一定的增减次序。
下面的程序将曲线颜色变浅, 对每个大洲增加了拟合曲线, 增加了适当的标题和坐标轴标签。 注意,这时不能使用统一的group = country映射, 否则拟合曲线就是对每个国家都单独有一条拟合曲线, 而不是每幅小图中仅有一条拟合曲线。 办法是仅在geom_line()中给出group = country的映射, 但在geom_smooth()中则不用group维。
p <- ggplot(data = gapminder, |
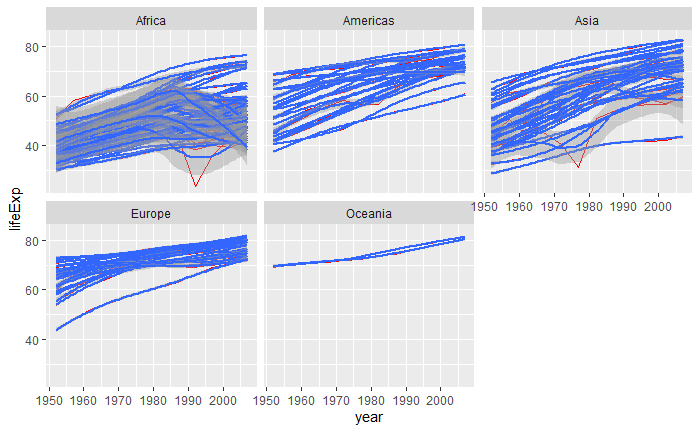
注意group = country的设置从ggplot()函数中转移到了geom_line()函数中, 否则就意味着拟合线也需要按照国家分组, 而不是按大洲分组。
facet_wrap()主要适用于按照一个分类变量的值将不同观测在不同小图中表现, 可以人为指定小图的行数和列数。 如果需要按照两个分类变量交叉分组分配小图, 可以用facet_grid()函数。
例如, 对gss_sm数据集,作小孩个数对年龄的散点图:
# socviz包的gss_sm数据集,在Rstudio中可以通过view(gss_sm)查看 |
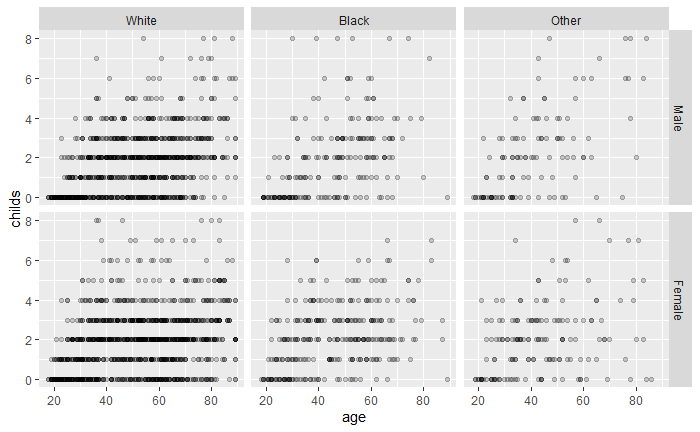
有过多的重叠点。 将观测按照性别(sex)和种族(race)交叉分组, 分配到不同的小图上:
p + geom_point(alpha = 0.2) + |
交叉分组时作小图时, sex ~ race这种写法使得不同性别对应到不同行, 不同种族对应到不同列。 在图形中增加拟合曲线:
p + geom_point(alpha = 0.2) + |
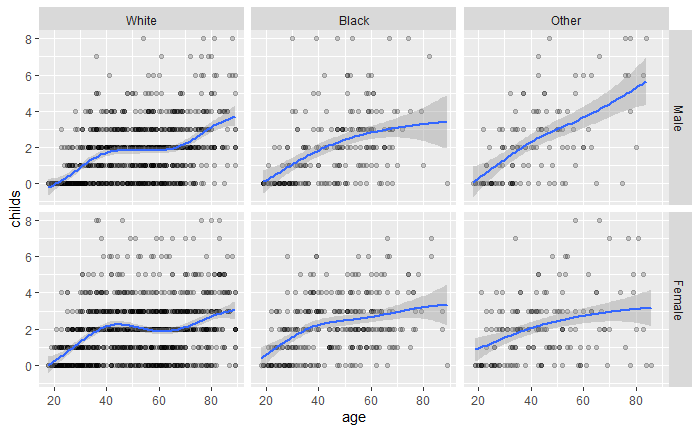
这里虽然没有映射group维, 但还是按性别和种族对数据集分成了6个子集, 每个小图中仅有一个自己的数据。
 微信
微信 支付宝
支付宝
