R语言学习笔记5
R语言教程-R编程2
16 程序控制结构
表达式
lam <- NA |
x <- -2 |
x <- c(40,50,60,80,90,100) |
如果需要对某个向量x按照下标循环, 获得所有下标序列的标准写法是seq(along=x), 而不用1:n的写法, 因为在特殊情况下n可能等于零,这会导致错误下标, 而seq(along=x)在x长度为零时返回零长度的下标。
# 另一种写法 |
用逻辑下标代替分支结构
# 生成数量与x向量等长的数字0 |
# 函数ifelse()可以根据一个逻辑向量中的多个条件, 分别选择不同结果。 |
循环结构
计数循环
对向量每个元素、矩阵每行、矩阵每列循环处理,语法为
for(循环变量 in 序列) 语句
# rnorm(5)生成5个标准正态分布随机数 |
等同于下面的意思
x <- c(2,-4,6,9,-10) |
计算:x~0~=0,x~n+1~=2x~n~+1,求S~n~ = 所有x(n=1…n)的和
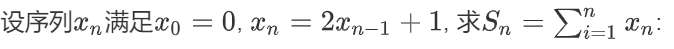
# 设n为10时 |
在R中应尽量避免for循环: 其速度比向量化版本慢一个数量级以上
# 前面的例子可以写为 |
x <- c(30,50,60,80,90) |
while循环和repeat循环
while:
用法:while(循环继续条件) 语句
其中的语句一般是复合语句。 仅当条件成立时才继续循环, 而且如果第一次条件就已经不成立就一次也不执行循环内的语句。
repeat:
用法:repeat 语句
repeat{ |
进行无条件循环(一般在循环体内用if与break退出)。
直到型循环至少执行一次, 每次先执行…代表的循环体语句, 然后判断是否满足循环退出条件, 满足条件就退出循环。
用break语句退出所在的循环。 用next语句进入所在循环的下一轮。

函数exp(1)可以计算e的值,下面用泰勒展开逼近计算e的值
# 模拟计算e值 |
if语句和while语句中用到条件。 条件必须是标量值, 而且必须为TRUE或FALSE, 不能为NA或零长度。
管道控制
数据处理中经常会对同一个变量(特别是数据框)进行多个步骤的操作, 比如,先筛选部分有用的变量,再定义若干新变量,再排序。 R的magrittr包提供了一个%>%运算符实现这样的操作流程。 比如,变量x先用函数f(x)进行变换,再用函数g(x)进行变换, 一般应该写成g(f(x)),用%>%运算符,可以表示成 x %>% f() %>% g()。 更多的处理,如h(g(f(x)))可以写成 x %>% f() %>% g() %>% h()。 这样的表达更符合处理发生的次序,而且插入一个处理步骤也很容易。
如果一个操作是给变量加b,可以写成add(b), 给变量乘b,可以写成multiply_by(b)。
17 函数
函数的自变量是只读的, 函数中定义的局部变量只在函数运行时起作用, 不会与外部或其它函数中同名变量混杂。
函数定义
函数定义使用function关键字,一般格式为:
函数名 <- function(形式参数表) 函数体
函数体是一个表达式或复合表达式(复合语句), 以复合表达式中最后一个表达式为返回值, 也可以用return(x)返回x的值。
如果函数需要返回多个结果, 可以打包在一个列表(list)中返回。 形式参数表相当于函数自变量,可以是空的, 形式参数可以有缺省值, R的函数在调用时都可以用“形式参数名=实际参数”的格式输入自变量值。
# 无参数示例图 |
# sqrt表示开根号 |
定义中的自变量x叫做形式参数或形参(formal arguments)。 函数调用时,形式参数得到实际值,叫做实参(actual arguments)。
R函数有一个向量化的好处, 在上述函数调用时,如果形式参数x的实参是一个向量, 则结果也是向量,结果元素为实参向量中对应元素的变换值。
函数定义中的形式参数可以有多个, 还可以指定缺省值。和python差不多,只是函数的表达式不一样。
fsub <- function(x, y=0){ |
这里x, y是形式参数, 其中y指定了缺省值为0, 有缺省值的形式参数在调用时可以省略对应的实参, 省略时取缺省值。
一个自定义R函数由三个部分组成: 函数体body(),即要函数定义内部要执行的代码; formals(),即函数的形式参数表以及可能存在的缺省值; environment(),是函数定义时所处的环境, 这会影响到参数表中缺省值与函数体中非局部变量的的查找。 注意,函数名并不是函数对象的必要组成部分。
函数调用
-
函数调用时最基本的调用方式是把实参与形式参数按位置对准
-
R函数调用时全部或部分形参对应的实参可以用“形式参数名=实参”的格式给出, 这样格式给出的实参不用考虑次序, 不带形式参数名的则按先后位置对准。
-
R的形参、实参对应关系可以写成一个列表, 如fsub(3, y=1)中的对应关系可以写成列表 list(3, y=1), 如果调用函数的形参、实参对应关系保存在列表中, 可以用函数do.call()来表示函数调用,
# 与fsub(3,y=1)一样 |
在自定义R函数的形参中, 还允许有一个特殊的…形参(三个小数点)。 在函数调用时,所有没有形参与之匹配的实参, 不论是带有名字还是不带有名字的, 都自动归入这个参数, 这个参数的类型是一个列表。 通常用来把函数内调用的其它函数的实参传递进来。
例如,sapply(X, FUN, …)中的形式参数FUN需要函数实参, 此函数有可能需要更多的参数。 例如,为了把1:5的每个元素都减去2,可以写成
sapply(1:5, fsub, y=2) |
实际上,R语法中的大多数运算符如+, -, *, /, [, [[, (, {等都是函数。 这些特殊名字的函数要作为函数使用,需要使用反向单撇号`包围
`*`(3,4) |
# 给1:5每个元素减去2 |
变量作用域
全局变量和工作空间
在所有函数外面(如R命令行)定义的变量是全局变量。 在命令行定义的所有变量都保存在工作空间 (workspace)中。 用ls()查看工作空间内容。 ls()中加上pattern选项可以指定只显示符合一定命名模式的变量,
tmp.ery <- "hexo gene" |
用save()函数保存工作空间中选择的某些变量; 用load()函数载入保存在文件中的变量。如:保存data变量
save(data,file='my-data.RData') |
局部变量
变量是计算机内存中的一段c储存空间,函数的参数(自变量)在定义时并没有对应的存储空间, 所以也称函数定义中的参数为“形式参数”。
函数一般在调用时赋予实参变量,形参和函数被赋值的变量都是局部的。局部变量仅在函数运行时存在,一旦退出函数局部变量就不存在了。
xv <- c(1,2,3) |
在扇面这个函数例子中的x,y形参在函数运行完毕后就不存在了。
修改自变量
# 在函数内修改变量值并将其作为函数返回值, 赋值给原变量。 |
在函数内部用赋值定义的变量都是局部变量, 即使在工作空间中有同名的变量, 此变量在函数内部被赋值时就变成了局部变量, 原来的全局变量不能被修改。 局部变量在函数运行结束后就会消失。
%in%用于判断前面一个向量内的元素是否在后面一个向量中,返回布尔值。
a <- c(1,6,9,"a","t") |
if('x' %in% ls()) rm(x) |
在函数内访问局部变量
函数内部可以读取全局变量的值,但一般不能修改全局变量的值。全局变量容易造成不易察觉的错误, 应谨慎使用,但有些应用中不使用全局变量会使得程序更复杂且低效。
在下面的例子中, 在命令行定义了全局变量x.g, 在函数f()读取了全局变量的值, 但是在函数内给这样的变量赋值, 结果得到的变量就变成了局部变量, 全局变量本身不被修改:
x.g <- 9999 |
在函数内部如果要修改全局变量的值,用 <<-代替<-进行赋值。
x.g <- 9999 |
 微信
微信 支付宝
支付宝
